Anycase.ai vs. General-purpose AI: What Happens When Legal AI Actually Knows Philippine Law
Tyra Delos Reyes

General-purpose AI chatbots like ChatGPT and Gemini are trained on global, web-based data. That includes laws and legal references from the U.S. and foreign jurisdictions.
They weren’t built to understand the Philippine legal system, which is not only jurisdiction-specific but “mestizo” in nature, blending civil law, common law, Islamic law, and indigenous traditions.
Anycase is different. It’s a specialized legal AI, purpose-built for Filipino lawyers and trained exclusively on Philippine jurisprudence, statutes, and issuances.
We had a simple question: can a specialized legal AI tool like Anycase outperform general-purpose models when it comes to Philippine law?
Using 120 questions from the 2024 Philippine Bar Examinations, we compared three systems side by side.
Anycase.ai – A specialized legal AI trained on Philippine law, with custom tools designed to maintain a daily-updated library from canonical sources
GPT-4o – General-purpose AI with no direct access to broad global data
GPT-4o with Web Search – General-purpose AI enhanced with open web search, but lacking structured access to Philippine legal databases and canonical sources
Anycase consistently outperformed the others, winning in 88% of head-to-head evaluations and delivering the most accurate, well-grounded, and contextually relevant answers:
Evaluation Metric | Anycase | GPT-4o with Search | GPT-4o (No Search) |
Answer Correctness | 75.8% reliability | 24.2% reliability | 12.5% reliability |
Groundedness | 0% fabricated (aka “hallucinated”) citations | 32.5% fabricated citations | 45.8% fabricated citations |
Context Relevance | 1.7% misleading answers | 29.2% misleading answers | 25.8% misleading answers |
Among the three systems tested, Anycase delivered the most accurate, well-grounded, and contextually relevant answers.
General-purpose AI models, even with web search:
Missed controlling law
Suggested misleading, irrelevant, or non-canonical sources
Misunderstood the structure of Philippine doctrines and jurisprudence
Read the full whitepaper here.

Measuring the helpfulness of legal AI for Philippine lawyers
As a team embedded in the legal practice, we saw that most AI evaluation methods don’t reflect the real-world consequences of legal work. AI models often sound confident, but can provide misleading, ungrounded answers that lead to dangerously incorrect legal conclusions.
That’s why we developed a legal AI RAG (Retrieval-Augmented Generation) Triad, a framework designed to evaluate whether an AI tool is genuinely helpful in Philippine legal scenarios, or whether it poses risks.
The RAG Triad: Raising the bar for legal AI usefulness
Each AI answer is evaluated along three dimensions:
Answer Correctness
Does the AI apply the correct legal doctrine, using reasoning that aligns with how Philippine courts interpret and resolve the issue?
Groundedness
Are all citations traceable to real, canonical Philippine legal sources, such as Supreme Court decisions, and laws published in the Official Gazette?
Context Relevance
Did the AI pull in all the essential authorities (statutes, doctrines, and recent rulings) that a competent Filipino lawyer would be expected to cite? Did it miss anything that could materially affect the outcome?
[Results] Built for PH law: Anycase beats general-purpose AI in 2024 Philippine Bar Exam with 88% win rate
Answer Correctness
Did the AI apply the correct legal doctrine, reason through it properly, and reach a conclusion consistent with how Philippine courts would decide the issue?


Anycase delivered legally sound, usable answers in 75.8% of cases, more than 3x higher than GPT-4o with Search (24.2%) and far ahead of GPT-4o without Search (12.5%).
GPT-4o frequently relied on outdated precedent or applied general doctrine without jurisdictional alignment.
GPT without search often misapplied law due to lack of retrieval capabilities.
Groundedness
Are the citations real, and can you trace every legal claim to an official Philippine legal source?


Anycase was the only system with 0% fabricated citations, ensuring every case and statute could be verified.
GPT-4o with Search fabricated sources in 32.5% of responses, often providing claims unsubstantiated by any legal references in the search results. The model was also unable to distinguish between canonical and non-canonical sources, often citing blogs, forums, or open web resources in its search results.
GPT without search also struggled, fabricating citations in 27.5% of outputs, risking professional reliability.
Context Relevance
Did the AI include all the key doctrines, statutes, and rulings that a competent Filipino lawyer would be expected to cite?

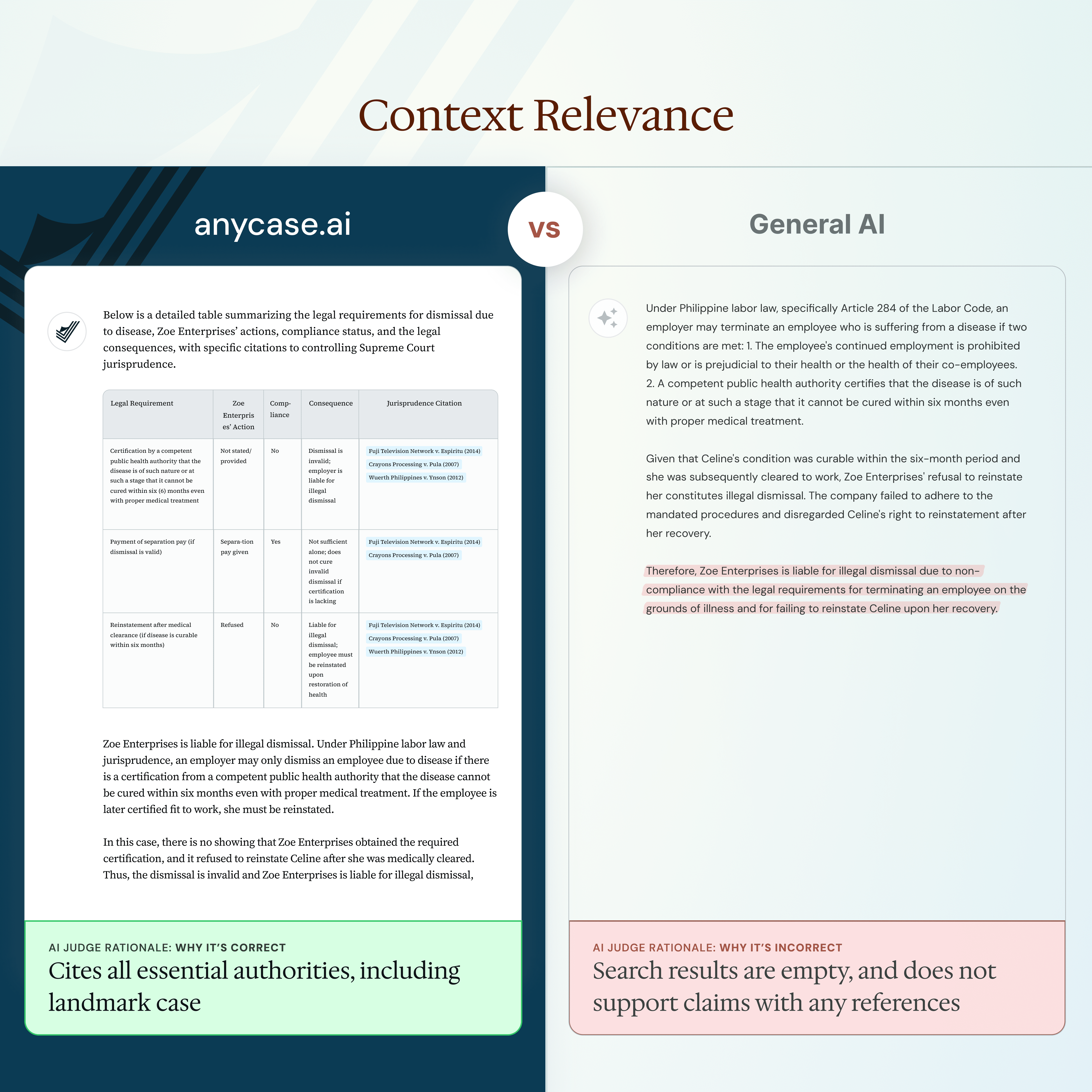
Anycase retrieved the full legal context in 49.2% of responses and avoided misleading or off-topic content in nearly all cases.
GPT-4o with Search returned misleading or incomplete context in 29.2% of responses, often omitting critical case law or mixing in irrelevant material.
GPT without search missed important authorities in 1 out of 4 answers, limiting its usefulness even when the conclusion seemed plausible.
The bottom line: Why Filipino lawyers need legal AI built for their system
For Filipino lawyers, using the wrong case or missing a key doctrine is a professional liability.
What this evaluation shows is that not all AI tools are built with that risk in mind.
Our whitepaper makes it clear: general AI tools frequently sound persuasive but fail where it matters most.
❌ Nearly 1 in 3 responses included hallucinated or unverifiable citation
❌ Missed controlling jurisprudence and applied outdated doctrine
❌ Provided incomplete or misleading context in over 25% of cases
❌ Cannot distinguish between canonical and non-canonical sources
Anycase was built specifically for Philippine legal practice, and it performs like it:
✅ More than 7 in 10 answers (75.8%) were immediately usable and legally sound. These are outputs a lawyer can rely on with minimal or no revision, usable for drafting pleadings, memos, or internal legal analysis.
✅ 100% of citations were real, verifiable, and traceable to Philippine sources
✅ Only 1.7% of responses included misleading context, compared to over 25% in the general-purpose AI models
✅ Pulls from a curated, jurisdiction-specific legal database updated daily
✅ Even lower-scoring outputs remained grounded and easy for lawyers to refine. Classified as Workload (0) under the RAG Triad, these answers weren’t misleading or risky. For the everyday lawyer, this means that Anycase’s outputs are safe to build on, not completely start over from.
When legal outcomes depend on accuracy, relevance, and trust, Filipino lawyers need more than a general chatbot.
We need a system built for our laws, our doctrine, and our standards.
That’s what Anycase delivers.
About the whitepaper: The RAG Triad
The RAG Triad reflects our commitment to advancing legal AI in the Philippines.
As a team that includes law students and practicing lawyers embedded in actual legal practice, we understand what makes AI truly useful, and dangerous, for Philippine law.
We created these benchmarks not just for ourselves, but for the broader legal tech community. At Anycase.ai, we believe that improving legal AI requires shared standards and transparent evaluation.
How we validate: The AI Judge system
Beyond human validation from our Legal Partners, we developed a sophisticated AI Judge using a rigorous two-stage protocol.
We tested if our AI Judge gives stable scores across multiple evaluations, using Krippendorff's α (statistical reliability measure). We then validated against gold standard answers from Philippine legal experts to ensure our AI Judge aligns with expert human judgment.
Want to evaluate our whitepaper findings?
This evaluation framework helps us, and you, build AI that gets consistently better.
We're actively seeking more external evaluators to expand our benchmark dataset and refine these standards. Because better evaluation means better AI for everyone. If you're interested in evaluating our findings, please reach out to us.
